
ML Pipelines for Supervised Learning
Regression & Classification Project
Developed supervised learning pipelines in Python to solve both regression and classification problems using real datasets. This project demonstrates the ability to preprocess structured data, build scikit-learn pipelines, train multiple models, and evaluate predictive performance with appropriate metrics.
Key Contributions:
- Regression Task (Customer Attributes Dataset):
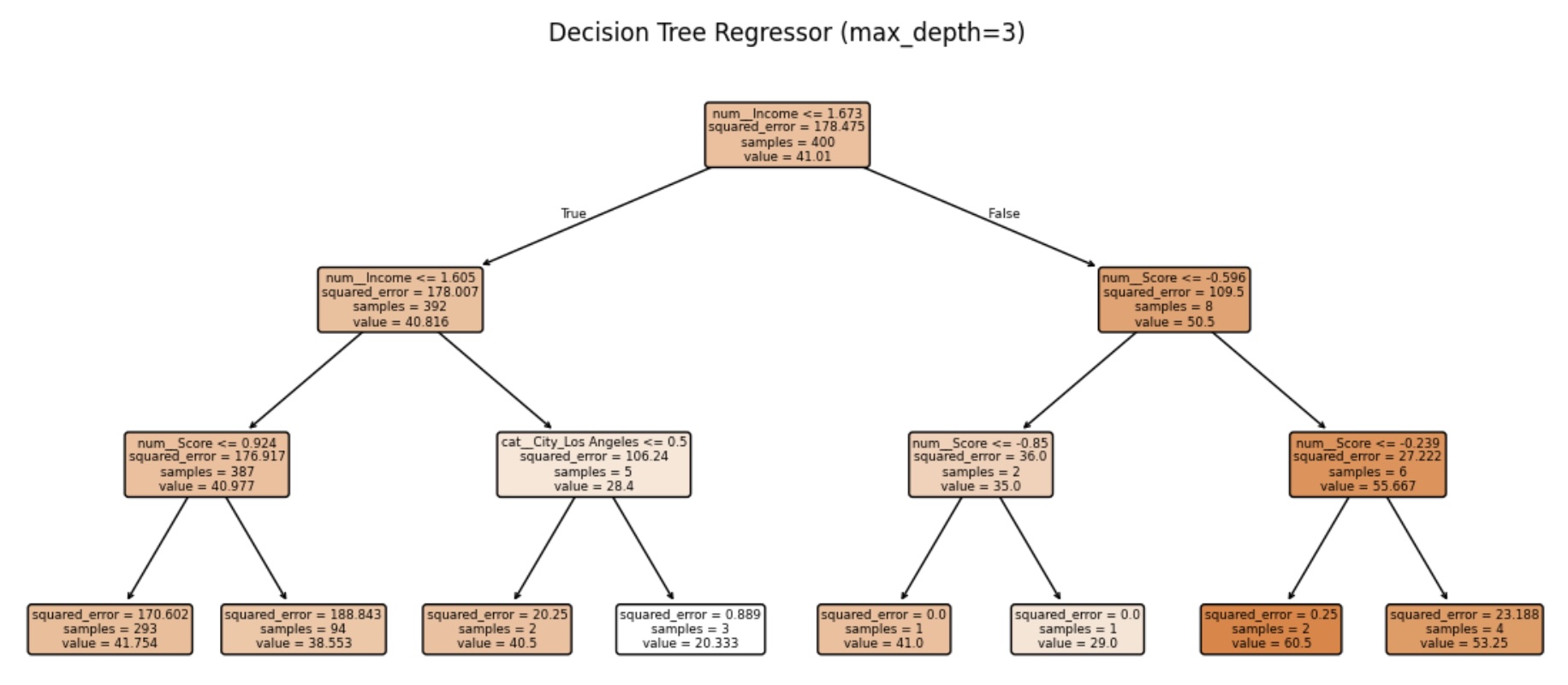
- Target: Customer age prediction from demographic and behavioral features.
- Implemented preprocessing with SimpleImputer, StandardScaler, and OneHotEncoder.
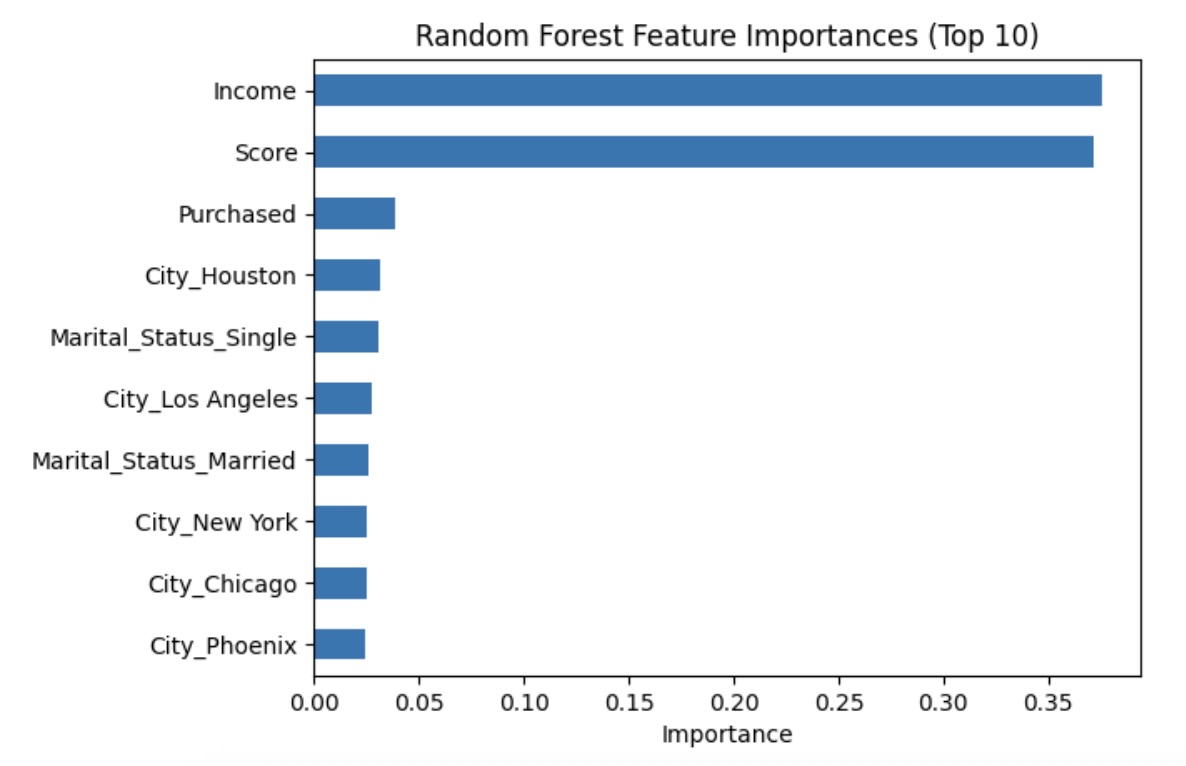
- Trained Linear Regression and Random Forest Regressor, compared performance with MSE and R².
- Classification Task (Sports Betting Dataset):
- Target: Match outcome prediction (Actual Winner vs Predicted Winner).
- Features: Team names, betting odds, draw odds, etc.
- Built pipelines with categorical encodings and scaling.
- Trained Decision Tree and Logistic Regression classifiers, evaluated with accuracy, precision, and recall.
Skills Demonstrated:
- Machine Learning (supervised regression & classification)
- Data preprocessing (handling missing values, categorical encoding, scaling)
- Pipeline construction with ColumnTransformer and Pipeline
- Model evaluation (MSE, R², accuracy, precision, recall)
- Python ML stack: scikit-learn, pandas, numpy, matplotlib, seaborn
Links:
Other Projects

MITRE ATT&CK Techniques
Machine Learning Pipeline to predict MITRE Att&cks based on categorical features from a cybersecurity dataset

Social Media Engagement Prediction
Machine Learning pipeline to predict engagement on social media posts using structured data